Prompts Don't Travel. Translate Them.
By Reza Motaghi

On this page
- The Core Problem with AI Prompt Portability
- Common Prompting Mistakes When Switching AI Models
- GPT vs. Claude vs. Gemini: A Look at Their Core Architectural Differences
- Session Memory Varies by Design
- Routing Logic Differs Silently
- Training Creates Distinct Thinking Patterns
- User Context Doesn't Travel
- How to Translate Any Prompt to Work Across All AI Models
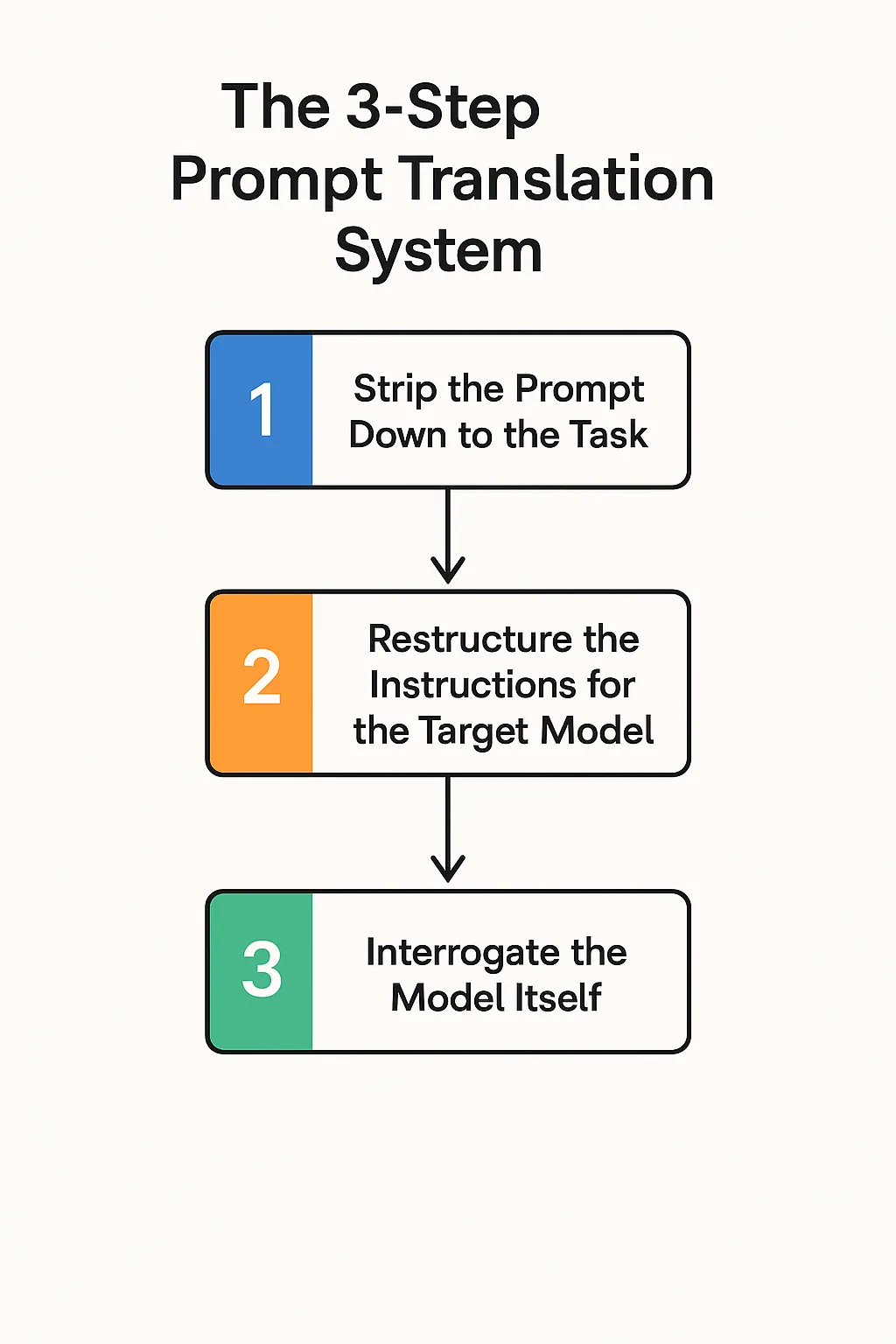
- The 3-Step Prompt Translation System
- 1. Strip the Prompt Down to the Task
- 2. Restructure the Instructions for the Target Model
- 3. Interrogate the Model Itself
- How 'Prompt Drift' Increases Costs in Enterprise AI Workflows
- Shifting Your Mindset from Prompt Reuse to Prompt Translation
- Frequently Asked Questions
- Why do my prompts work in GPT but fail in Claude?
- Do I need to rewrite every prompt when switching AI models?
- How long does prompt translation typically take?
- Which AI models are most different from each other?
- Should I stick with one AI model instead of switching?
- What if my translated prompt still doesn't work?
- Can I make one universal prompt that works everywhere?
- Is prompt translation worth the effort for simple tasks?
You reused your prompt. The output broke. Welcome to the hidden cost of multi-model AI workflows.
Most solopreneurs and professionals think prompt engineering is about what you say.
But the real issue is who you're saying it to, and how they listen.
Every AI model thinks differently. When you reuse prompts between models, you're not transferring instructions—you're miscommunicating across different cognitive architectures. And it's costing you hours every week.
This post breaks down:
- Why prompt portability failures aren't your fault, but are your responsibility
- How solo builders and enterprises alike get stuck in "fix-it" loops
- A 3-step translation system to make your prompts model-agnostic
Let's fix the root issue—once, and for all.
The Core Problem with AI Prompt Portability
You wrote a beautiful prompt. GPT gave you exactly what you wanted.
So you tried the same prompt in another model.
Your GPT prompt doesn't work in Claude—it spit out nonsense.
Gemini turned it into a horoscope.
Now you're "debugging" the AI instead of solving the task.
Sound familiar?
This isn't a creative problem. It's architectural.
Different models don't just interpret language. They apply different logic stacks—preference trees, token scoring, instruction parsing, and more.
So when a prompt breaks, it's not that you wrote it wrong.
You just translated it into a dialect the model doesn't understand.
Common Prompting Mistakes When Switching AI Models
We assume prompt portability should be seamless.
After all, it's just words in → words out, right?
But here's what actually happens:
- You copy a prompt to a new model.
- The output is wrong, confusing, or low-quality.
- You tweak and re-run until it feels "closer."
- You second-guess the model or yourself.
- Eventually, you give up and go back to GPT or your first model.
This loop wastes hours. And worse, it erodes trust in your tools.
Across enterprise teams and solo workflows, I've watched this slow bleed kill velocity.
Builders spend more time comparing outputs than creating anything.
GPT vs. Claude vs. Gemini: A Look at Their Core Architectural Differences
Large language models aren't just different flavors of the same interface.
Each one interprets input through a unique logic stack—their own way of reading context, parsing tasks, and assigning relevance. And that stack varies not just by model, but by how and when you access it.
Session Memory Varies by Design
Some models remember your ongoing session and build on prior exchanges, while others treat each prompt independently due to architectural differences in how transformers handle context windows.
That means the exact same instruction might rely on assumed context—but if that context doesn't persist in the new model, the whole prompt collapses.
Routing Logic Differs Silently
Even within the same model, your input might be processed differently depending on unseen factors—load balancing, regional routing, model versioning.
So yes, a prompt that worked perfectly yesterday may fail today—not because you changed anything, but because the system did.
Training Creates Distinct Thinking Patterns
Each model was trained on a different corpus, with different weights, objectives, and reinforcement layers—a process that fundamentally shapes how AI systems process and respond to instructions.
Some favor logical breakdowns. Others lean toward storytelling or analogy.
Your prompt style fits one model's cognition—and clashes with another's.
User Context Doesn't Travel
Your Claude isn't mine.
Your GPT doesn't think like mine.
Over time, models adapt to your tone, vocabulary, and structure preferences. But that's invisible—until you switch models and wonder why everything feels off.
⚠️ A prompt that performs brilliantly in one model may collapse in another—not because it's bad, but because it assumes a shared context that doesn't exist. This is a direct consequence of how LLMs process requests under the hood.
This isn't your fault.
But it is your responsibility to adapt.
Models don't respond to cleverness.
They respond to clarity.
How to Translate Any Prompt to Work Across All AI Models
The 3-Step Prompt Translation System
Here's how to stop firefighting and start translating.
This is the same system I use across enterprise deployments—and in my own solo work when switching models is necessary.
1. Strip the Prompt Down to the Task
Every prompt contains hidden assumptions: formatting, tone, implied knowledge.
Start by identifying the core task:
"Summarize this article"
"Extract top 3 objections"
"Create a checklist for beginners"
No flourishes. Just task.
This is your anchor.
2. Restructure the Instructions for the Target Model
Once you've stripped the prompt to its core task, the next step is reformatting—not rewording.
Most prompt rewrites fail because they adjust language, not structure.
Structure is what models actually latch onto.
Once you've isolated the core task, rebuild it in a format that the target model processes cleanly:
Break the task into clear, ordered steps
Define the expected output format—bullet list, markdown, JSON, etc.
Be explicit about tone, persona, and constraints
Understanding Claude vs GPT prompt formatting makes a huge difference here:
Claude often improves when the prompt sets a role and simplifies tone:
"You're a calm analyst. Extract 3 key themes in bullet form. Use plain language, no assumptions."
Gemini performs better with clear framing and formatting guidance:
"Act as a product strategist. Return a markdown checklist with implementation steps—not general advice."
Don't rely on the model to "figure it out." Spell it out.
Models don't respond to cleverness.
They respond to clarity.
3. Interrogate the Model Itself
This is the diagnostic move most builders skip.
Add this to the end of your prompt:
"What part of this request is unclear or underdefined?"
You'll be shocked by how often the model replies:
"It's unclear what format you expect."
"You didn't specify whether to prioritize speed or depth."
"I'm unsure if this is for a beginner or advanced audience."
Now you're not guessing. You're debugging with the model—exactly the kind of adaptive feedback loop I use to turn failures into repeatable systems.
This is universal AI prompting at its core.
It's not reuse.
It's adaptation.
How 'Prompt Drift' Increases Costs in Enterprise AI Workflows
In enterprise environments, we often A/B test models for cost, compliance, or latency.
What derails projects isn't just model performance. It's prompt drift.
Teams reuse the same prompts across vendors—OpenAI, Anthropic, Mistral—then spend sprint cycles adjusting the output instead of the instruction.
The fix?
We standardize the intent, not the syntax.
Each model gets a prompt tailored to its logic stack, not the one we wish it had.
That insight saved one client 18 hours per week across 6 workflows.
Solo? You can save even more—because you move faster.
Shifting Your Mindset from Prompt Reuse to Prompt Translation
You're not switching tools.
You're switching thought architectures.
Expecting seamless prompt portability between GPT, Claude, and Gemini is like giving the same camera to a painter, a sculptor, and a filmmaker—and expecting identical work.
When the output breaks, it's not a sign to rewrite.
It's a sign to translate.
If the task matters, stick with one model.
If you must switch, don't copy-paste—rebuild. Translate.
That's how real builders operate.
That's how solo workflows stay sharp.
That's how enterprise systems scale without collapse.
—
Want weekly frameworks like this?
Subscribe to the One-Person Startup for no-fluff insights that compound.
Frequently Asked Questions
Why do my prompts work in GPT but fail in Claude?
Each AI model has a different cognitive architecture - they process instructions, context, and preferences differently. What works in GPT's logic stack may not align with Claude's training patterns, causing output quality to drop or break entirely.
Do I need to rewrite every prompt when switching AI models?
Not necessarily. Simple prompts often work across models, but complex workflows with specific formatting, tone, or multi-step instructions usually need translation using the 3-step system outlined above.
How long does prompt translation typically take?
For basic prompts, translation takes 2-5 minutes. Complex multi-step prompts may require 10-15 minutes to properly restructure and test. This upfront investment saves hours of debugging later.
Which AI models are most different from each other?
GPT and Claude have the most distinct differences in instruction parsing and context handling. Gemini falls somewhere between them. Models from the same company (like GPT-3.5 vs GPT-4) are more similar but still require some adjustment.
Should I stick with one AI model instead of switching?
If your workflow is mission-critical and works well with one model, stick with it. Only switch models when you need specific capabilities (like Claude's longer context window) or when cost/speed requirements change.
What if my translated prompt still doesn't work?
Use step 3 of the translation system - ask the model directly "What part of this request is unclear?" The model will often identify specific issues you missed, like undefined output format or missing context.
Can I make one universal prompt that works everywhere?
While perfect universality is difficult, you can create more portable prompts by being extremely explicit about format, tone, and expectations. However, model-specific optimization usually yields better results.
Is prompt translation worth the effort for simple tasks?
For basic tasks like "summarize this" or "list the main points," translation overhead isn't worth it. Focus translation efforts on complex, repeatable workflows where quality consistency matters.